
What is Apache Spark ?
Very simply put, Apache Spark is a cluster computing platform designed for fast and large scale data processing.
Why Spark?
For most of their history, the Moore's law applied to processing power of computers that is, computers became faster every year with the increasing number of transistors on a chip board. As a result of that most of the applications were designed to run only on a single processor. This trend however stopped due to a major heat dissipation limitation around 2004-05. We didn't have the technology to cool the chipsets with the amount of heat being dissipated on them as the number of transistors just kept on increasing. Therefore in keeping with the Gustaffson's law, the ecosystem switched towards adding more parallel CPU cores all running at the same speed. This change meant that suddenly applications needed to be modified to add parallelism in order to run faster. This provoked the need for parallel computing clusters like Hadoop Map Reduce.

Moreover, the cost to store 1 TB of data continues to drop by roughly two times every 14 months, meaning that it is very inexpensive for organizations of all sizes to store large amounts of data. This set the stage for new programming models such as Spark. Why? Because Spark supports In - Memory Processing.
Key features
Unified Platform
Writing big data applications by reading data off of a SQL server and then doing Machine Learning over it, is all made feasible with one scan over data using Spark.
Computational Engine
Spark is a “computational engine” that is responsible for scheduling, distributing, and monitoring applications consisting of many computational tasks across many worker machines, or a computing cluster. One can use Spark with many persistent storage systems, distributed file systems such as Apache Hadoop, key-value stores such as Apache Cassandra, and message buses such as Apache Kafka, cloud storage systems such as Azure Storage and Amazon S3. However, Spark neither stores data long term itself, nor favors one over another. Spark’s focus on computation makes it different from earlier big data software platforms such as Apache Hadoop. Hadoop included both a storage system (the Hadoop file system, designed for low-cost storage over clusters of commodity servers) and a computing system (MapReduce), which were closely integrated together.
Speed
On the speed side, Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. One of the main features Spark offers for speed is the ability to run computations in memory.
Generality
Spark is designed to cover a wide range of workloads that previously required separate distributed systems, including batch applications, iterative algorithms, interactive queries, and streaming which is often necessary in production data analysis pipelines. Spark is designed to be highly accessible, offering simple APIs in Python, Java, Scala, and SQL, and rich built-in libraries. It also integrates closely with other Big Data tools. In particular, Spark can run in Hadoop clusters and access any Hadoop data source.
RDD
Spark has two ways of looking at data at each node. Either as an RDD (Resilient Distributed Datasets) or a DataFrame. An RDD is a fundamental data structure of Spark. It is an immutable, partitioned set of data. It can contain a set of any Java, Scala or Python objects (including custom classes). They contain the lineage of the data (the steps used to create them), so are resilient as they can be easily recreated. An RDD can either be a basic table of objects or can be a set of key and value pairs. There are some special functions for working with key based RDDs which provide great functionality and power (e.g. reduceByKey and groupByKey). A key feature is fault tolerance as RDD's have full lineage of the data.
Lazy Execution
The lineage also allows for lazy evaluation, in other words, nothing is evaluated until a result is requested. Spark has two types of functions for this process– Transformations and Actions. Transformations reshape the input RDD to a new RDD. A simple example of a transformation would be a map extracting a couple of values or a filter selecting a subset of rows. Actions cause the RDD to be evaluated and return some results. A simple example would be the count function which returns the number of rows in the RDD. One interesting thing is the while reduce is itself an action returning a single item, but reduceByKey is a transformation returning a new RDD of keys and values.
Spark vs Hadoop MapReduce
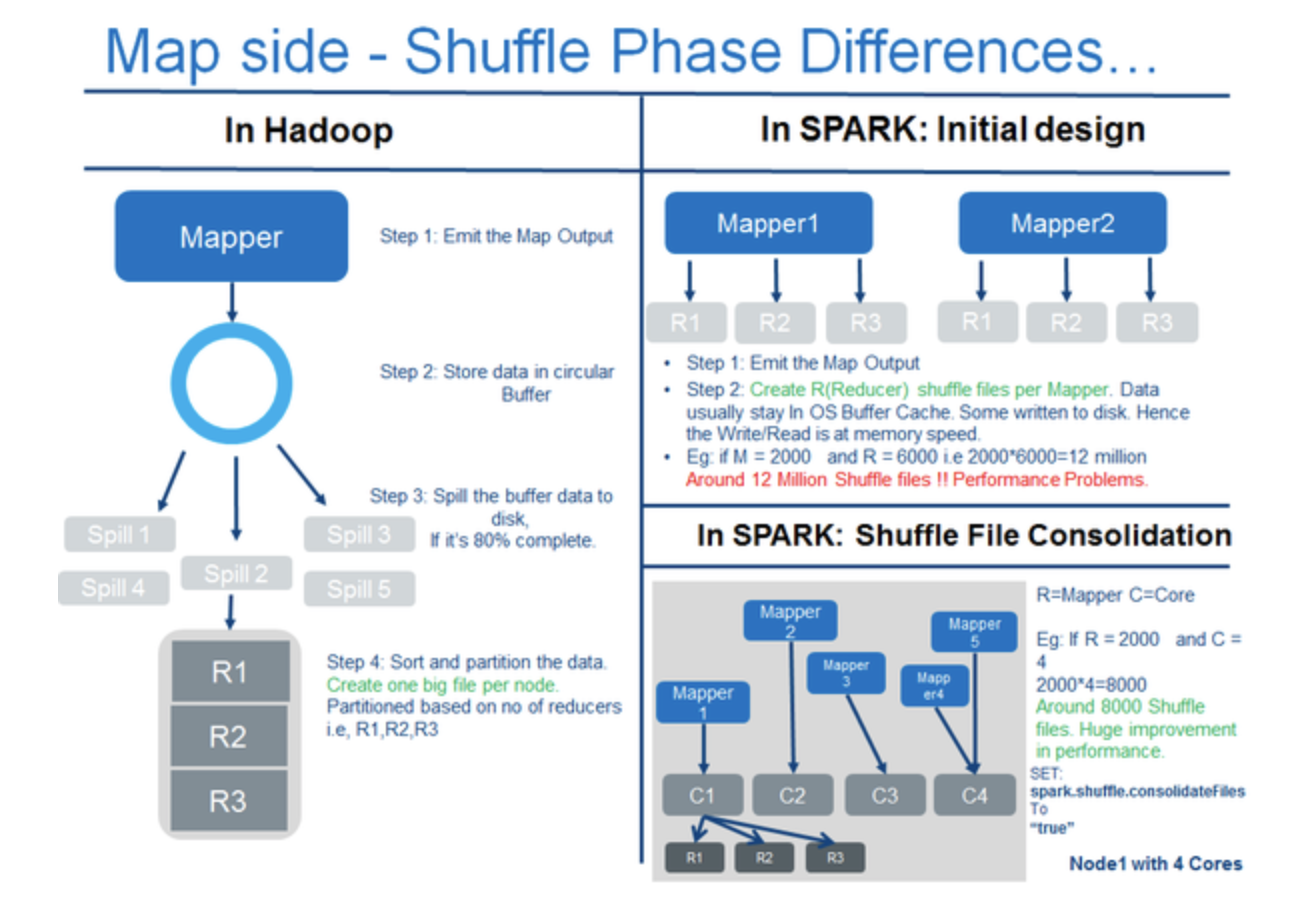
Differences in mapping between Spark and Hadoop
Map tasks in Hadoop emits data in Key:Value pairs, then output is stored in circular buffers which is around 100 mb in size. The output is stored onto the disk if this buffer is 80 mb full. All these spill files are merged into one big file which is sorted and then partitioned for all reducers to work parallely.
Map tasks in Spark emit outputs which are written to OS Cache, all map tasks on one core are consolidated into a single file and then partitioned into the number of reducers, so the number of files generated is equal to the number of cores times the number of reducers. For ex, If there are 6000(R) and 4 (C) Cores, the number of files will be (R*C) 6000*4=24000 files.
Differences in Reduce

The Reduce phase of Hadoop MapReduce pulls the shuffle files for each reducer in memory, the data is spilled to disk if memory is 70% full. Spill files are merged to form bigger files (merging and sorting) and reduce is called finally called.
The Reduce phase of Spark pulls data on reducers, which is written directly to memory. Overflowing data spills to disk and the reducer is called.
Conclusions
Apache Spark is a cluster computing platform designed to be fast, speed side and extends the popular MapReduce model to efficiently supports more type of computations, including interactive queries and stream processing. It uses RDD, so that the intermediate results could be stored in-memory as mentioned before to reduce the disk read and write overhead. With the lineage property of RDD, Spark doesn’t have to make disk checkpoints for the purpose of recovery since the lost data could be reconstructed with the existing RDD, therefore SPARK is very fault tolerant as compared to other distributed computing platforms. Delayed Scheduling with lazy evaluation is one awesome property to handle tasks effectively.
References
https://people.eecs.berkeley.edu/~kubitron/courses/cs262a-F13/projects/reports/project16_report.pdf
[Apache Spark: a unified engine for big data processing](201611 Apache Spark A Unified Engine for Big Data Processing.pdf). Zaharia, Matei, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng et al. Communications of the ACM 59, no. 11 (2016): 56-65.
https://www.quora.com/What-is-the-difference-in-idea-design-and-code-between-Apache-Spark-and-Apache-Hadoop
https://medium.com/explore-artificial-intelligence/introduction-to-apache-spark-81457568e416